What is Open Data?
July 20, 2020 by Annabel van Daalen
What do the Victorian physician John Snow, a Danish toilet-locating app, and our president, Rufus, have in common? The punchline: they were all inspired by open data. This article explores a term still unfamiliar to many and explains why making data open is one of the most important challenges of the 21st Century.

Photo by Chuttersnap on Unsplash
The year is 1854 and London-based physician John Snow is investigating the causes of cholera. After hearing rumours connecting the drinking pump at Broadstreet to the disease, Snow begins to suspect cholera as water-borne. To test his theory, he cross-references data about cholera deaths with the location of the city’s water wells. His findings confirm his suspicions that areas with the highest mortality rates have one thing in common: their water source. Snow’s discovery saved thousands of lives, led to the construction of London’s sewage systems and has been credited with the founding of modern epidemiology.
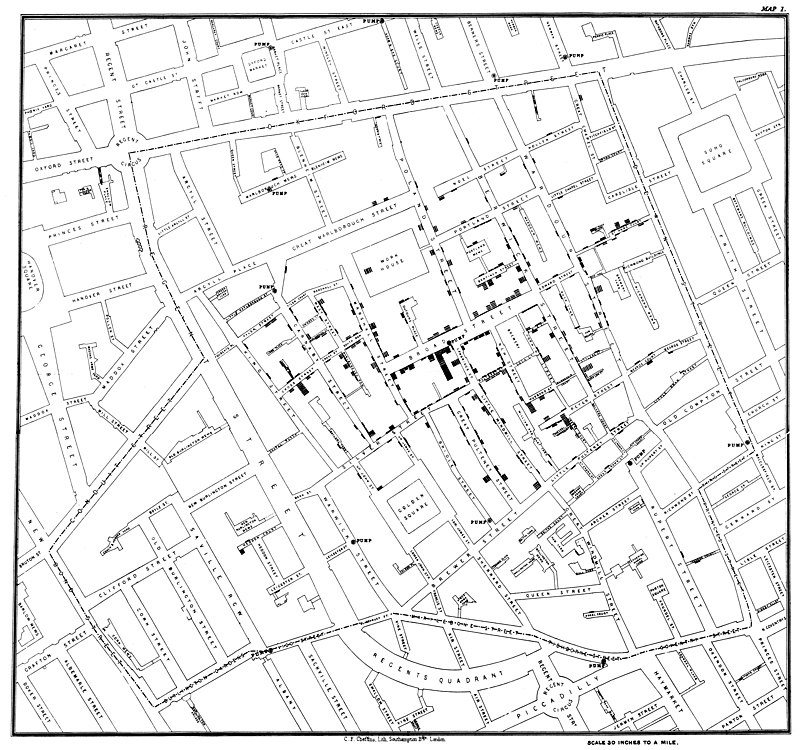
Original map by John Snow showing the clusters of cholera cases in the London epidemic of 1854, drawn and lithographed by Charles Cheffins. Source: Wikipedia.
You might be wondering what this has to do with open data. It was certainly neither a term nor a concept familiar to John Snow when he created the map shown above. However, the way in which the Victorian was able to combine what we would today consider two (apparently unconnected) ‘datasets’ to discover patterns that would change the course of the future is testament to the value that comes from making public data open. Without access to locational data on cholera deaths, Snow may never have been able to prove his theory. His work is a prime example of one of open data’s driving philosophies: if you open data up to the world, someone out there somewhere will find a use for it - generating new value, driving breakthroughs and sparking innovation.
# Open Data 101
At Datopian, we have the pleasure of working closely with our friends at the Open Knowledge Foundation (OKF), a non-profit working towards a fair, free and open future. They are the creators of a very popular Open Data Handbook for anyone interested in opening up their data. The handbook contains the Open Definition, widely considered the official definition of open data, which reads as follows:
‘Open data is data that can be freely used, re-used and redistributed by anyone - subject only, at most, to the requirement to attribute and sharealike.’
TIP
The Open Data Handbook notes that open data should be ‘open’ in two senses. Firstly, data should be legally open, meaning it is available under an open data license that permits anyone to access, reuse and redistribute it. Secondly, data should be technically open, meaning that it is available for no more than the cost of reproduction and comes in a format that is machine readable (ie. so that it can be shared digitally). This latter stipulation ensures that, even if certain data is legally open, it is still readily accessible and downloadable by anyone; that is to say, there’s not much point in having open data if you can’t access or use it.

Through a clear statement of the criteria for openness, those producing open data can ensure that their data is open to the same degree as open datasets from elsewhere. Open data runs on the premise of interoperability, meaning that it needs to be joined together (literally ‘inter-operate’) with other open data if it is to have the most impact. As made apparent by the example of John Snow, datasets are most valuable when pieced together, as in a jigsaw.
# So, when is data not completely open?[1]
For data to be truly open in the terms laid out by the Open Definition, and for it to flow seamlessly throughout society to wherever it is needed most without barrier or hinderance, data must not be any of the following:
| Data is not completely open if it is… | For example, if… |
|---|---|
| …restricted to a certain group or purpose. | …it is only available for use in education, within the United States or for non-commercial endeavours. |
| …packaged in a proprietary format. | …you have to purchase Microsoft Office to be able to access it. |
| …in a format that is not machine-readable. | …it is trapped on paper or another format that does not easily lend itself to being processed by a computer. |
| monetized. | …it is only available for more than a one-off, reasonable production cost. |
| …restricted by terms of service. | …the data comes with rules such as restrictions on dissemination. |
| …altered. | …information information has been changed, updated or removed without any indication that an alteration has taken place. |
| …regulated by registration or membership requirements. | …anyone has to identify themselves or provide a justification for accessing the data. |
| …restrained by electronic or physical barriers to access. | …you have to visit a certain place in person or submit an online form. |
| …not published in real time. | …there is a significant delay between the data being collected and it being published online. |
| …from a secondary source. | …the data doesn’t come with metadata about how that data was collected so that users may verify that the data was recorded correctly. |
| …incomplete. | …only a portion of the raw data is published. |
# What kinds of data should be open, then?
There are lots of different kinds of data that can and should be open. This is data that tells us things about the world and societies we live in. Groups of data that have the most to contribute if made open are outlined in the Open Data Handbook. We’ve provided a summary below.

National History Museum in London. Photo by Nick Cozier on Unsplash
- Cultural: collected by galleries, libraries, archives and museums.
- Scientific: produced as part of scientific research, from astronomy to zoology.
- Financial: such as government accounts (expenditure and revenue) and information on financial markets (stocks, shares, bonds etc).
- Statistical: produced by statistical offices, such as censuses.
- Meteorological: used to understand and predict the weather and climate.
- Environmental: related to the natural environment, e.g. pollutant levels and sea water quality.
# And, what should not be open?
At this point, we should emphasize that some forms of data should not, of course, be made open. Personally identifiable information - that is, any data specific to a certain individual - should not be made open. Likewise, some kinds of government data are protected by national security standards. When we talk about open data, we specifically mean public data, ie. data that is within the public interest and should, therefore, be made open.
# Success Stories
The Open Data Handbook is replete with examples of ways in which people are using open government data to make a difference. Often, these are small-scale, national projects seeking to enhance public life in some way. The Danish app findtoilet.dk, which locates all Danish public toilets, grew out of one woman’s wish to give friends with bladder problems the confidence to go out again.
The Handbook also shows how even more established, private businesses have benefitted from open data. In fact, many well-known companies rely on data being open: Google, for example, uses open transport data in a GTFS (General Transit Feed Specification) format to enrich their Google Maps applications, and Google Translate uses the enormous volume of EU documents that appear in all European languages to train its translation algorithms.[2] Google’s example is testimony to the fact that open data simulates innovation and competitivity, rather than stifling it.
Across the globe, there is also an abundance of examples of more far-reaching, international projects that have used open data to enact global change on a monumental scale. One such example is the response of the OpenStreetMap community to the earthquake in Haiti in 2010. In response to the crisis, major satellite companies released high-resolution satellite imagery under open licenses that facilitate wide distribution and use. This gave OpenStreetMap volunteers the information they needed to digitize roads and buildings, creating the most detailed map of Haiti in existence in just a few weeks. This map was to prove invaluable to the organizations involved in response and reconstruction.[3]
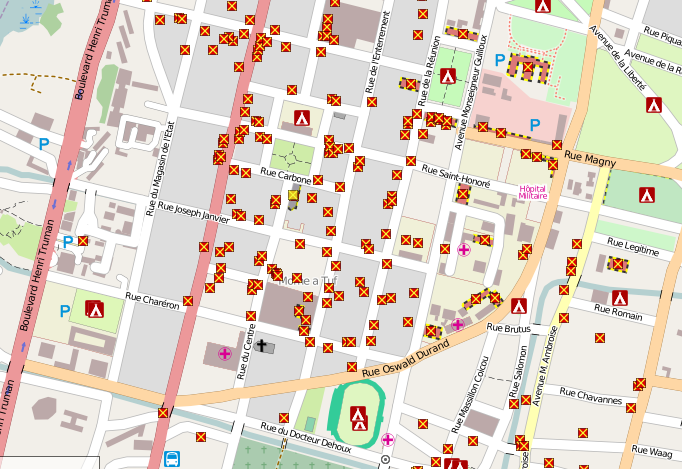
Image shows damaged buildings and refugee camps mapped within OpenStreetMap using special GeoEye/DigitalGlobe imagery. Source: wiki.openstreetmap.org.
TIP
Open data really does save lives - see another example on how open data reduces mortality rates in UK hospitals.
There have, however, been moments in history in which projects that changed life as we know it through being made open narrowly missed being made closed, controlled by privately-owned companies. In his book The Open Revolution: Rewriting the Rules of the Information Age (2018), our president, Dr. Rufus Pollock (or just Rufus to you and me), explores the example of the Human Genome. The release in 2000 of the first draft of our shared genetic code was an achievement compared to the moon landings and the invention of the wheel. Economists estimate that opening up this information resulted in a 20-30% increase in research and product development; its publishing enabled medicine to better understand the genes that hold the key to illnesses such as cancer. Yet, as Rufus elaborates, this information very nearly fell into the hands of a private enterprise with the right to keep it closed and selectively share it - for a price.[4]
# Why else is open data important?
Aside from contributing to global well-being and driving innovation, open data saves public money. Take, for example, the story of how open data helped expose one of the greatest tax frauds in Canada’s history, recovering $3.2 billion.[5] Another high-impact story tells how a senior UK government official used open data about government spending to save £4 million pounds in 15 minutes.[6]
In addition, making data open increases accountability. If enterprise and government had to publish all their non-personal data and lay it out for all to see, imagine the sorts of questions the press may start to ask. For a telling example of how open data can hold organizations to account, see this video clip from Rufus: https://streamable.com/e/50f75w
Click here to watch the full video.
# We’ll leave you with this:
According to a study by the management consultancy McKinsey, open data can help create $3 trillion a year of value in seven areas of the global economy. So far, however, this potential remains largely untapped.
Let’s change that. Join the Open Revolution.
Want to work with Datopian? We are data management experts providing open-source tooling and related services to organisations worldwide. Check our website for more information or contact us.
© Datopian (CC Attribution-Sharealike (by-sa)).
- https://sunlightfoundation.com/policy/documents/ten-open-data-principles/;
https://opendatacharter.net/principles/ - https://opendatahandbook.org/guide/en/why-open-data/
- https://opensource.com/osm;https://blogs.worldbank.org/latinamerica/4-years-looking-back-openstreetmap-response-haiti-earthquake
- Pollock, Rufus. 2018. The Open Revolution: Rewriting the Rules of the Information Age. A/E/T Press. ↩︎
- https://eaves.ca/2010/04/14/case-study-open-data-and-the-public-purse/
- https://opendatahandbook.org/value-stories/en/saving-4-million-pounds-in-15-minutes/↩︎